雷竞技app最新版raybet雷竞技东北大学图书馆数字化过程物理材料利用几个不同的工作流处理打印文档、照片、和模拟音频和视频记录。数字化工作流程的每一步,从收集审查扫描到元数据描述,进行彻底的对细节的关注,可能需要数年时间才能完全过程集合。例如,大约160万张照片《波士顿环球报》图书馆收藏由东北大学档案馆和特殊集雷竞技app最新版raybet雷竞技合可能需要几十年才能完成!
如果这些步骤可以提高使用人工智能技术来完成的部分工作,释放员工将更多精力投入在工作流的元素需要人类的注意呢?读了一个非常简短的概述人工智能和三个潜在的选择处理《波士顿环球报》馆藏和其他数字图书馆收藏。
人工智能和机器学习是什么?
人工智能(AI)是一个广泛的术语用于许多不同的技术,试图模仿人类推理。机器学习(ML)是人工智能的一个子集,一个程序教自己如何学习和理性。项目学习通过使用一种算法来处理现有的数据和发现模式。每个模式预测评估和得分根据准确的预测可能是也可能不是,直到达到一个可接受的水平的准确性预测。
毫升可以监督或无监督,根据结果所需的类型。监督学习是当指令提供协助算法将研究人员学习如何识别模式。无监督学习算法时美联储数据和发现自己的模式,研究人员可能不知道。
道德
我们进行这项工作,重要的是要注意,人工智能技术是人造的,因此人类偏见中直接嵌入技术本身。因为可以使用人工智能技术在如此大的规模,这些偏见造成的潜在的负面影响大于需要标准人类努力的工具。尽管人们很容易接受并尽快使用一个很有用的技术,这是一个研究领域,我们必须确保工作符合我们的制度伦理和隐私实践才能实现。
人工智能或ML技术可以用来帮助过程数字集合?
光学字符识别:最广为人知和使用形式的人工智能在数字集合实践可能识别印刷文本使用光学字符识别,或光学字符识别。光学字符识别是一个过程,分析印刷文本和提取文本对象,如字母,单词,句子。结果可以直接嵌入在这个文件中,像一个PDF OCR文字,或单独存储,像METS-ALTO文件,或两者兼而有之。

OCR现代文本文档工作相当好,尤其是英语,但OCR的一个特别的挑战是历史文献。更多关于这个挑战,我建议历史和多语种OCR的研究议程,一个相当NULab发布的最新报告。
我们已经可以看到在图书馆的使用OCR的好处数字库服务与OCR文本嵌入到文件,文件的全文提取并存储在文本文件中。文本索引,提高文本文件通过检索文件的可发现性与搜索条件相匹配的文件的元数据或全文。

HTR:手写文本识别、HTR像OCR,但对于手写,不打字的,文本。笔迹非常独特的个体,给教学带来了一个困难的挑战机器来解释它。HTR严重依赖有大量数据训练模型(在这种情况下,大量的数字化图像手写),所以即使一次模型是准确地训练一组的笔迹,它可能不是有用的准确解释另一组。Transkribus项目试图导航这一挑战通过创建批手写数据训练集。研究人员提交至少100转录为特定的笔迹图像集Transkribus和Transkribus使用集作为训练数据来创建一个HTR模型来处理剩下的手写文本的语料库。HTR呼吁《波士顿环球报》收集的后背照片包含手写文本描述图像,包括摄影师的名字,照片拍摄日期,分类信息,描述或者一个地址。
计算机视觉:计算机视觉是指人工智能技术,使机器能够处理图像和视频,本质上训练机器“看见”。这种类型的人工智能机器是特别具有挑战性,因为它需要学习如何观察和分析图片和理解的内容。计算机视觉算法训练来识别模式不同的物体或人,试图准确地分类和识别模式。在东北校园的图片,例如,计算机视觉算法可以识别建筑对象或对象或树对象的人。
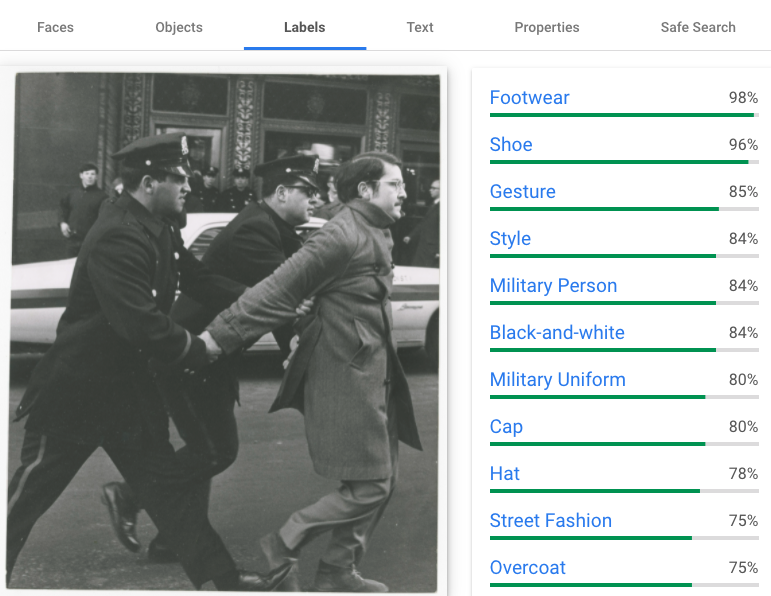
在数字工作流集合,使用时产生的输出计算机视觉工具将需要评估其有效性和准确性。在上面的例子中,返回的术语来描述图像技术出现在照片(主题是穿鞋和帽子和大衣),但条件不充分捕捉图像的精神(一个人被拘留在一个演示)。
有很多使用计算机视觉伦理担忧,尤其是识别人脸和分配的情绪。如果我们使用这个特定的技术,它可以生成关键词或其他描述性元数据可能不是现在的波士顿环球报收集的图片,但是我们需要小心,以确保不嵌入问题评估过程描述,像一个抗议的形象描述为一场骚乱。
计算机视觉已经被应用在一些数字工作流集合。卡内基梅隆大学图书馆开发了一个称为内部工具皮帮助档案员提高元数据。一个档案管理员使用软件来标记选择图片,然后程序返回其他图像标识在视觉上相似,无论其盒,文件夹,允许档案管理员轻松地应用相同的标记那些看起来很相似的图像,而无需手动寻找。
许多其他方面的人工智能和ML技术需要研究和评估之前他们可以集成到我们的数字集合的工作流。我们需要评估工具和确定需要培训员工的技能来执行工作。我们也会继续看领导人在这个领域深入探究世界的人工智能图书馆的工作。
推荐的资源:
机器学习+库:报告字段/柯莱恩的状态:https://blogs.loc.gov/thesignal/2020/07/machine-learning-libraries-a-report-on-the-state-of-the-field/
数字图书馆、智能数据分析和增强描述/布拉斯加-林肯大学:https://digitalcommons.unl.edu/libraryscience/396/